
OpenAI致力于防止AI毁灭人类?
集微网消息,据The Register报道,OpenAI表示,它正在将五分之一的计算资源用于开发机器学习技术,以阻止超级智能系统“失控”。
这家旧金山人工智能初创公司成立于2015年,其既定目标始终是安全地开发通用人工智能。这项技术目前还不存在,专家们对于这项技术究竟会是什么样子或何时到来存在分歧。
 (资料图片仅供参考)
(资料图片仅供参考)
尽管如此,OpenAI打算拿出20%的处理能力,并成立一个由联合创始人兼首席科学家Ilya Sutskever领导的新部门,以某种方式防止未来机器危害人类。OpenAI之前曾提出过这个话题。
“超级智能将是人类发明的最具影响力的技术,可以帮助我们解决世界上许多最重要的问题,”这位未来的物种救世主本周表示。
“但超级智能的巨大力量也可能非常危险,并可能导致人类丧失权力,甚至人类灭绝。”
OpenAI相信,能够超越人类智能并压倒人类的计算机系统可能在这十年内被开发出来。
“管理这些风险将需要新的治理机构并解决超级智能协调的问题:我们如何确保人工智能系统比人类更聪明地遵循人类的意图?”该公司补充道。
已经存在使模型与人类价值观保持一致(或者至少尝试使模型保持一致)的方法。这些技术可能涉及“人类反馈强化学习”(RLHF)。 通过这种方法,你基本上是在监督机器来塑造它们,使它们的行为更像人类。
尽管RLHF帮助ChatGPT等系统不易生成有毒语言,但它仍然会引入偏见,并且难以扩展。 它通常涉及必须以不是很高的工资招募大量人员来提供模型输出的反馈——这种做法有其自身的一系列问题。
据称,开发人员不能依靠少数人来监管一项会影响许多人的技术。OpenAI的对齐团队正试图通过构建“一个大致达到人类水平的自动对齐研究员”来解决这个问题。OpenAI希望构建一个人工智能系统,而不是人类,让其他机器与人类价值观保持一致,而无需明确依赖人类。
在我们看来,这将是人工智能训练人工智能变得更像非人工智能。有点先有鸡还是先有蛋的感觉。
例如,这样的系统可以搜索有问题的行为并提供反馈,或者采取其他一些步骤来纠正它。为了测试该系统的性能,OpenAI表示,它可以故意训练未对齐的模型,并观察对齐AI清理不良行为的效果如何。新团队设定的目标是在四年内解决对齐问题。
“虽然这是一个令人难以置信的雄心勃勃的目标,我们不能保证成功,但我们乐观地认为,集中一致的努力可以解决这个问题。有许多想法在初步实验中显示出了希望,我们有越来越有用的进展指标 ,我们可以使用今天的模型来实证研究其中的许多问题,”该机构总结道。
“解决问题包括提供证据和论据,让机器学习和安全社区相信问题已经解决。如果我们对我们的解决方案没有很高的信心,我们希望我们的发现能让我们和社区做出适当的计划。 ”
标签:
 查看更多滚动
查看更多滚动
甘肃:“寒凉”持续盘踞 “甘味”农产备受考验

(上海战疫录)专访上海一居民区书记:坚持!背后6000多居民等着我们

西宁公安严厉打击涉疫违法犯罪 依法处理案件72起123人

甘肃渭源:千年渭水文化蕴“写生热” 校地合作塑学生文化涵养

5月16日起 西宁市部分区域有序开放
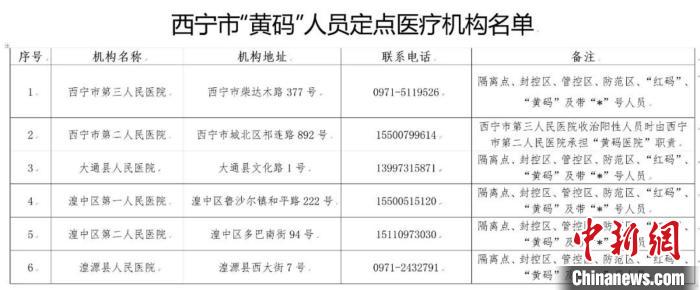
青海西宁:设置“黄码医院”保障重点人群医疗服务需求
- 07-10OpenAI致力于防止AI毁灭人类?
- 07-10杭叉集团获760台产品订单,总货值近1.5亿元
- 07-10瑞达期货:豆类下方支撑仍强
- 07-10深南电路(002916.SZ):公司部分PCB产品有应用于AI服务器领域
- 07-10本周公开市场共有130亿元人民币逆回购到期
- 07-10全国高校毕业生基层就业卓越奖 厦门两位毕业生榜上有名
- 07-10雪灵兽怎么抓(雪灵兽)
- 07-10恶魔猎手破解版 新恶魔猎人破解版2.2.4
- 07-09商汤科技王晓刚:大模型为自动驾驶技术带来新飞跃
- 07-09假的!套路!别信!
- 07-09上海交通大学邱慈观:面对碳挑战,企业应该不畏艰难,积极发挥影响力
- 07-09临港新片区管委会主任陈金山:新片区正在加快洋山港扩规模升级 吞吐量目标为4000万标箱
- 07-09手指月牙代表什么部位(手指月牙代表什么)
- 07-09红杉中国“抢滩”新加坡与红杉印度竞争?双方回应:信任基础强大 合作多于竞争
- 07-09“根本吃不完!”这份“招生减章”上新了!
- 07-09湖南科技大学三下乡主题活动丨清廉宣讲:在童心深处播撒清廉种子
- 07-09规范33类81项公证事项
- 07-09完成固定资产投资3049亿元 全国铁路年中“成绩单”来了→
- 07-09上半年全国铁路发送旅客17.7亿人次 接近2019年同期水平
- 07-09首届“艺术与科学训练营”开营
- 07-09台湾屏东县海域先后发生5.4级、4.7级地震
- 07-09百余名媒体记者走进固原,为宁夏冷凉蔬菜打call!
- 07-08蚯蚓养殖的市场前景如何_蚯蚓养殖的市场前景
- 07-08教育系统多措并举持续为未就业毕业生提供就业指导服务
- 07-08witkin witkin怎么读)
- 07-08严控大拆大建 留住历史文脉 城市更新明确底线要求
- 07-08日本皇冠2.0T综合评测及驾驶体验
- 07-08全球顶尖学者专家齐聚,畅谈AI前沿技术的当下与未来→
- 07-08被证监会处罚后 虚增业绩的航天动力相关责任人被上交所纪律处分
- 07-08最新动态:北约峰会拟商议对乌长期援助计划 俄一生产炸药工厂爆炸