
什么是爬网(爬走网络) 快报
1、网络爬虫就是为其提供信息来源的程序,网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常被称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,已被广泛应用于互联网领域。
2、2、搜索引擎使用网络爬虫抓取Web网页、文档甚至图片、音频、视频等资源,通过相应的索引技术组织这些信息,提供给搜索用户进行查询。
3、网络爬虫也为中小站点的推广提供了有效的途径。
 (资料图片)
(资料图片)
4、拓展资料:网络爬虫另外一些不常使用的名字还有蚂蚁,自动索引,模拟程序或者蠕虫。
5、随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。
6、搜索引擎(Search Engine),例如传统的通用搜索引擎AltaVista,Yahoo!和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。
7、但是,这些通用性搜索引擎也存在着一定的局限性,如:(1) 不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
8、(2)通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
9、(3)万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
10、(4)通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
11、网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
12、另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
13、蚂蚁(ant),自动检索工具(automatic indexer),或者(在FOAF软件概念中)网络疾走(WEB scutter),是一种“自动化浏览网络”的程序,或者说是一种网络机器人。
14、它们被广泛用于互联网搜索引擎或其他类似网站,以获取或更新这些网站的内容和检索方式。
15、它们可以自动采集所有其能够访问到的页面内容,以供搜索引擎做进一步处理(分检整理下载的页面),而使得用户能更快的检索到他们需要的信息。
16、网络爬虫始于一张被称作种子的统一资源地址(URLs)列表。
17、当网络爬虫访问这些统一资源定位器时,它们会甄别出页面上所有的超链接,并将它们写入一张"待访列表",即所谓"爬行疆域"(crawl frontier)。
18、此疆域上的统一资源地址将被按照一套策略循环访问。
19、如果爬虫在他执行的过程中复制归档和保存网站上的信息,这些档案通常储存,使他们可以被查看。
20、阅读和浏览他们的网站上实时更新的信息,并保存为网站的“快照”。
21、大容量的体积意味着网络爬虫只能在给定时间内下载有限数量的网页,所以要优先考虑其下载。
22、高变化率意味着网页可能已经被更新或者删除。
23、一些被服务器端软件生成的URLs(统一资源定位符)也使得网络爬虫很难避免检索到重复内容。
24、网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
25、下面是小编为您整理的关于网络爬虫是什么,希望对你有所帮助。
26、网络爬虫是什么网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
27、另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
28、网络爬虫就是为其提供信息来源的程序,网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常被称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,已被广泛应用于互联网领域。
29、2、搜索引擎使用网络爬虫抓取Web网页、文档甚至图片、音频、视频等资源,通过相应的索引技术组织这些信息,提供给搜索用户进行查询。
30、网络爬虫也为中小站点的推广提供了有效的途径,爬虫业务离不开代理ip,需要提供直接加我吧,可以全国试用1 爬虫技术研究综述 引言� 随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。
31、搜索引擎(Search Engine),例如传统的通用搜索引擎AltaVista,Yahoo!和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。
32、但是,这些通用性搜索引擎也存在着一定的局限性,如:� (1) 不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
33、� (2) 通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
34、� (3) 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频/视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
35、� (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
36、� 为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。
37、聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。
38、与通用爬虫(general�purpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
39、� 1 聚焦爬虫工作原理及关键技术概述� 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
40、传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件,如图1(a)流程图所示。
41、聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。
42、然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,如图1(b)所示。
43、另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
44、� 相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:� (1) 对抓取目标的描述或定义;� (2) 对网页%B。
本文到此分享完毕,希望对大家有所帮助。
标签:
 查看更多滚动
查看更多滚动
甘肃:“寒凉”持续盘踞 “甘味”农产备受考验

(上海战疫录)专访上海一居民区书记:坚持!背后6000多居民等着我们

西宁公安严厉打击涉疫违法犯罪 依法处理案件72起123人

甘肃渭源:千年渭水文化蕴“写生热” 校地合作塑学生文化涵养

5月16日起 西宁市部分区域有序开放
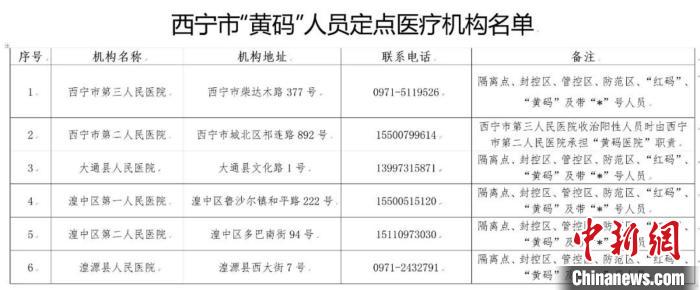
青海西宁:设置“黄码医院”保障重点人群医疗服务需求
- 06-06什么是爬网(爬走网络) 快报
- 06-06最新资讯:飞机托运液体规定多少费用_飞机托运液体规定
- 06-06打造“一棵草到一杯奶”全产业链生态圈-世界百事通
- 06-06全球关注:专家建议:不同年龄段“呵护”眼睛有侧重
- 06-06环球热讯:华阳集团:今年以来HUD量产客户数量持续增加
- 06-06快看:100字运动会广播稿范文
- 06-06当前焦点!文案爱情温柔
- 06-06有路山海梦(关于有路山海梦介绍)_通讯
- 06-06停车区域、禁行路段……高考期间海口各考点出行指南来了 环球微动态
- 06-06世界即时:这是我的战争攻略_这是我的战争超全攻略解析
- 06-06众友回家行-上海站|沉浸式体验一汽-大众华东备件中心_世界热门
- 06-06观速讯丨中和热的定义一定要强调强酸强碱吗_中和热的定义
- 06-06婚礼答谢宴一般在婚礼后多久,婚礼答谢宴要给红包吗
- 06-06减肥吃什么水果好而且瘦的快_减肥吃什么水果好|天天滚动
- 06-06“强制同化100万西藏儿童”?外籍特约观察员独家探访西藏寄宿制学校
- 06-052019大众捷达发布 更大 更空气动力 更先进 世界播资讯
- 06-05环球观点:周震南父亲涉嫌拖欠1千万执行款,再次成为被执行人!
- 06-05天天讯息:2023昆明希望刺演出信息(时间+地点+票价+阵容)
- 06-05深交所:珠海和佳医疗设备股份有限公司股票终止上市
- 06-05【世界快播报】深交所:顺利办信息服务股份有限公司股票终止上市
- 06-05当前关注:铠侠推出第二代UFS 4.0嵌入式闪存设备
- 06-05环球焦点!2023年中国超声波设备行业发展分析 超声波设备行业市场投资前景预测
- 06-05华平投资近期将旗下两上海商业地产项目售予红杉中国、平安集团
- 06-05中辰股份(300933)6月5日主力资金净卖出174.83万元|焦点快看
- 06-05【时快讯】四大品类饮料步步涨价 竞争之法或在价格之外
- 06-05梅西效应,巴黎已掉粉150万!社媒遭围攻,亨利:这是姆巴佩地盘_速读
- 06-05【环球财经】5月Judo Bank澳大利亚服务业PMI回落至52.1点
- 06-05烟台火车站电话 烟台火车站|环球观焦点
- 06-05四大品类饮料步步涨价 竞争之法或在价格之外|天天热消息
- 06-05本月底截止!这笔钱,别忘了退